SQL server 一些命令
主键约束 PRIMARY KEY
外键约束 FOREIGN KEY
默认值约束 DEFAULT
自增ID IDENTITY(1,1) 第一个种子值,第二个步长
2
3
4
5
# 一.定义
数据:描述事物的符号记录。
数据库:一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库管理系统:一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS
数据库系统:指在计算机系统引入数据库后的系统,一般由数据库,数据库管理系统,应用系统和数据库管理员构成。
登录名:服务器方的一个实体,使用一个登录名只能进入服务器,但是不能让用户访问服务器中的数据库资源。每个登录名的定义存放在master数据库的syslogins表中。
用户名:一个或多个登录对象在数据库中的映射,可以对用户对象进行授权,以便为登录对象提供对数据库的访问权限。用户定义信息存放在每个数据库的sysusers表中。
SQLSERVER把登录名与用户名的关系称为映射。用登录名登录SQLSERVER后,在访问各个数据库时,SQLSERVER会自动查询此数据库中是否存在与此登录名关联的用户名,若存在就使用此用户的权限访问此数据库,若不存在就是用guest用户访问此数据库(guest是一个特殊的用户名,后面会讲到)。 一个登录名可以被授权访问多个数据库,但一个登录名在每个数据库中只能映射一次。即一个登录可对应多个用户,一个用户也可以被多个登录使用。好比SQLSERVER就象一栋大楼,里面的每个房间都是一个数据库.登录名只是进入大楼的钥匙,而用户名则是进入房间的钥匙.一个登录名可以有多个房间的钥匙,但一个登录名在一个房间只能拥有此房间的一把钥匙。 链接或登录Sql Server服务器时是用的登录名而非用户名登录的,程序里面的链接字符串中的用户名也是指登录名。
B-tree:一个节点可以拥有多于两个子节点的二叉查找树。
根结点至少有两个子节点
每个结点有M-1个key,升序排列
。。。。
特点:
1.关键字集合分布在整棵树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一个二分查找
与B+tree的区别:
(1)有K个子节点的节点必然有k个key
(2)非叶子结点仅具有索引作用,跟记录有关的信息均放在叶子节点中
(3)树的所有叶子节点构成一个有序链表,可以按照Key排序的次序遍历全部记录
B+树的优点在于: 1.由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。 因此访问叶子节点上关联的数据也具有更好的缓存命中率。 2.B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。 而且由于数据顺序排列并且相连,所以便于区间查找和搜索。 而B树则需要进行每一层的递归遍历,相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于: 由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
触发器:触发器是一种特殊类型的存储过程,它被分配给某个特定的表。当对这个表进行插入、更新或删除操作时, 自动调用触发器执行触发器里规定的操作.
触发器是确保数据完整性和一致性的基本有效的方法。
和表相关联,可以看作是表的一部分;
不能直接引用,通过insert/update/delete自动激活;
属于事务机制;
同一类型的触发器在表上可以有多个
特点:
- 不接受用户参数,也不返回用户参数;
- 事件驱动,自动调用;存储在表上。
- 对数据库中的相关表进行级联更新和删除
- 强制比Check约束更复杂的数据完整性。
- 可以引用其他表中的列。
分为:插入型触发器,删除型触发器,更新型触发器
--创建触发器
CREATE TRIGGER 触发器名
ON 表名
FOR delete/ insert/ update
AS 触发器操作
--删除触发器
DROP TRIGGER 触发器名
--启用,停用触发器
ALTER TABLE 表名 DISABLE|ENABLE TRIGGER 触发器名
2
3
4
5
6
7
8
9
10
# 1.模式
sqlserver数据库的结构为: 数据库–>模式–>表/视图/存储过程/函数/触发器 模式就是数据库中一类对象的集合
定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
当模式名缺省时,自动创建一个模式名为用户名的模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT> --cascade(级联), restrict(限制)
cascade(级联)表示在删除模式的同时把该模式中所有的数据库对象全部删除 restrict(限制)表示如果该模式中已经定义了下属的数据库对象,如表或视图等,则拒绝该删除语句的执行。
# 2.表的定义、删除与修改
2.1 定义基本表
列级约束有六种:主键Primary key、外键foreign key 、唯一 unique、检查 checck 、默认default 、非空/空值 not null/ null
表级约束有四种:主键、外键、唯一、检查
外键参考必须是唯一性索引
创建一个模式就是建立了一个数据库(命名空间)
CREATE TABLE <表名> (<列名> <数据类型> [列级约束条件]
, <表级完整性约束条件>)
2
[例1]
CREATE TABLE Student
(Sno CHAR(7) PRIMARY KEY,
Sname CHAR(20) UNIQUE,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
2
3
4
5
6
7
[例2]
CREATE TABLE Course
(Cno CHAR(4) PRIMARY KEY,
Cname CHAR(40),
Cpno CHAR(4),
Ccredit SMALLINT,
FOREIGN KEY Cpno REFERENCES Course(Cno)
);
--Cpno是外码
2
3
4
5
6
7
8
CREATE TABLE SC
(Sno CHAR(7),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY(Sno,Cno),
FORENGIN KEY Sno REFERENCES Student(Sno),
FORENGIN KEY Cno REFERENCES Course(Cno)
);
2
3
4
5
6
7
8
2.2 数据类型
# 3.模式与表
方法一: 在创建表时,显示给出模式名
CREATE TABLE S-T.Student(.....)
方法二: 创建模式时同时创建表
方法三: 设置所属模式
# 4.修改表
使用 ALTER TABLE 修改
ALTER TABLE <表名>
[ADD <新列名> <数据类型> <完整性约束>] --增加新列
[DROP <完整性约束名>]
[MODIFY <列名> <数据类型>] --修改字段类型
--添加字段
ALTER TABLE 表名 ADD 字段名 INT DEFAULT 0
--修改字段名
EXEC sp_rename Student.Ssex,SEX
--修改字段类型
ALTER TABLE 表名 ALTER COLUMN 字段名 类型
--修改字段默认值
ALTER TABLE 表名 DROP CONSTRAIT 约束名
ALTER TABLE 表名 ADD CONSTRAIT 约束名 DEFAULT (('默认值')) for 字段名
--添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 约束名 FOREIGN KEY(字段名) REFRENCES 被引用表名(字段名)
--删除字段
ALTER TABLE DROP COLUMN 字段名
--删除约束 先获取表有哪些约束,再根据名字删除
sp_helpconstraint 表名
ALTER TABLE DROP CONSTRAINT 约束名
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
tip::: 介绍
添加字段时若非空时需要添加一个默认值,例如
ALTER TABLE 表名 ADD 字段名 NOT NILL DEFAULT 0
修改字段类型时有默认值需要先删除约束,再修改。
:::
ALTER TABLE Student ADD S_en DATE;
ALTER TABLE Student MODIFY Sage INT; --修改原有列属性可能会破坏
ALTER TABLE Student DROP UNIQUE(Sname)
2
3
使用DROP TABLE 删除表。
DROP TABLE Student;
# 5.索引的建立与删除
建立索引是加快查询速度的有效手段。分为聚集索引和非聚集索引
UNIQUE表示唯一索引,CLUSTER表示聚簇索引。
CREATE [UNIQUE|CLUSTER] INDEX 索引名 ON 表名(列名|ASC(DESC))
CREATE UNIQUE INDEX S ON Student(Sno,DESC)
2
3
删除索引: DROP INDEX 索引名
# 二.数据查询
SELECT [ALL|DISTINCT] <目标列表达式>
FROM <表名或视图名>
WHERE <条件表达式>
GROUP BY <列名> HAVING <条件表达式>
2
3
4
# 1.单表查询
SELECT DISTINCT Sno
FROM SC; --去重
2
1.1查询满足条件的元组,通过 WHERE 实现
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,<,>,>=,<=,!=,<>,!>,!< |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,NOT IS NULL |
| 多重条件 | AND,OR,NOT |
SELECT Sname FROM Student WHERE Sdept='CS';
SELECT Sname,Ssex FROM Student WHERE Sdept NOT IN ('CS','MA','IS')
SELECT Sname,Sno,Ssex FROM Student WHERE Sname LIKE '刘%'; --查询所有姓刘的学生姓名,学号和性别
SELECT Sname FROM Student WHERE Sname LIKE '欧阳_'
SELECT Sno,Cno FROM SC WHERE Grade IS NULL
SELECT Sname FROM Student WHERE Sdept='CS' AND Sage <20;
2
3
4
5
6
7
8
1.2 ORDER BY 子句:对查询结果按照一个或多个属性列的升序(ASC)或降序(DESC)排列,默认为升序。
SELECT Sno,Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC;
2
3
4
1.3聚集函数
COUNT,SUM,AVG,MAX,MIN
COUNT([DISTINCT|ALL],[*|列名])
1.4GROUP BY子句:将查询结果按照某一列或多列的值分组,值相等的为一组
SELECT score FROM sc GROUP BY score
HAVNIG短语指定筛选条件
HAVING作用于组,从中选择满足条件的
WHERE作用于表或者视图,从中选择满足条件的
例如使用了GROUP BY短语就使用HAVING
# 2.连接查询
2.1等值与非等值连接查询 (内连接:也称为等值连接,返回两张表都满足条件的部分)
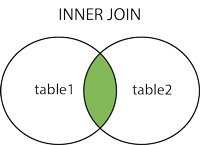
SELECT * FROM Teacher
SELECT Course.*,Teacher.*
FROM Course,Teacher
WHERE Course.TId=Teacher.TId --等值查询,连接符不是‘=’的就是非等值连接查询
01 语文 02 02 李四
02 数学 01 01 张三
03 英语 03 03 王五
2
3
4
5
6
7
8
自然连接:等值连接中把目标列重复的属性列去掉
2.2自身连接 需要为表取别名
2.3外连接
外连不但返回符合连接和查询条件的数据行,还返回不符合条件的一些行。外连接分三类:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN)暂时就学会这些
2.4复合连接
WHERE子句中有多个条件
# 3.嵌套查询
1.IN
SELECT sname from Student WHERE sid in ( SELECT sid FROM sc WHERE score>80)
# 三.视图
# 1.建立视图
CREATE VIEW <视图名> [列名,列名...]
AS 子查询
[WHERE CHECK OPTION]
2
3
子查询可以是任意SELECT语句,但通过不允许含有ORDER BY 子句和DISTINCT 短语
WHERE CHECK OPTIN对视图进行update,insert,delete时要保证行满足视图定义中的谓词条件(即子查询中的条件表达式);
# 2.删除视图
DROP VIEW <视图名>
# 3.查询视图
视图就相当于一个虚拟表,所以所有对基本表的查询语句,对视图也同样适用
# 4.视图更新
对视图的更新最终会转换成对基本表的更新。 可用操作有update,insert,delete,
# 例子
CREATE TABLE zuo
(ID INT IDENTITY(1,1) PRIMARY KEY,
COL INT DEFAULT(100),
SEX INT CHECK(SEX=0 OR SEX=1),
RAD INT FOREIGN KEY REFERENCES S_id(id))
2
3
4
5
# 四.实例
--MySQL根据timestamp类型字段查询当日,本月数据
select * from __ where DATE_FORMAT(timestamp字段,'%Y-%m-%d') = DATE_FORMAT(CURDATE(),'%Y-%m-%d');
select * from __ where DATE_FORMAT(timestamp字段,'%Y-%m') = DATE_FORMAT(CURDATE(),'%Y-%m');
--上月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format(now( ), '%Y%m' ) ,date_format(时间字段名, '%Y%m')) =1
2
3
4
5
来自 blog
https://blog.csdn.net/wenjoy/article/details/102777470
https://www.begtut.com/sql/func-mysql-period-diff.html